Instâncias Reservadas: suporte a família de instâncias
O AWS sempre tem evoluído e melhorado o seu modelo de instâncias reservadas. No começo era necessário comprar uma RI escolhendo, entre outros parâmetros, tipo e zona de disponibilidade. Flexibilizou-se então a alocação genérica dentro da região e mais recentemente o modelo passou a valer para qualquer tamanho dentro do tipo de família – entenda-se por família, o grupo que a instância faz parte, por exemplo, família T2: t2.nano, t2.micro, t2.small, t2.medium, etc.
Para mais detalhes do modelo técnico, veja o post oficial sobre as RIs. É importante notar a questão dos pontos / peso por tipo de servidor.
Com esta mudança o que é importante avaliar?
- além de verificar o tipo de instância, cheque se possui outros tipos dentro da mesma família – pode ganhar com otimização de custos usando ‘famílias’;
- está mais tranquilo comprar uma RI. Se precisar fazer um upgrade (dentro da mesma família) a RI ainda consumirá horas parciais sem perder o investimento;
- entendimento da alocação: conceito de horas parciais – uma instância pode consumir 0,5 hora de RI e 0,5 hora sob demanda;
- nem sempre comprar instância reservada pode ser vantajoso – verifique se uma estratégia de parar/iniciar servidores (ou mesmo upgrade/downgrade – especialmente se trocar a família) não fica mais em conta.
O Cloud8 pode ajudá-lo a entender como o AWS aloca as horas: quais são os servidores utilizados e como o AWS distribui horas/pontos dentro das famílias e regiões. Veja como ficou a aplicação de ‘Controle de RIs’.

Neste cenário, 2 instâncias m3.medium equivalente a 1488 horas no mês ou 2976 pontos (medium = 2 pontos) foram compradas. O AWS distrubuiu o uso em 5 servidores, sendo um deles m3.large que consumiu 100h de m3.medium (50 horas cheias de m3.large na prática). Notem que não há critério em como o AWS alocou as horas, mas é importante ver que o uso foi 100%, sem desperdício!

Também agrupamos o relatório por Auto Scaling Groups no lugar de mostrar instâncias individuais. Isto facilita o entendimento e a leitura de como as instâncias vão sendo alocadas (se não fosse este agrupamento, poderia haver dezenas de servidores com tempo de vida de poucas horas poluindo a interpretação).
Caso tenha usado tags nas instâncias, o custo e uso das RIs também será mostrado nos relatórios de tags.
Perfis: suporte a Automação de tarefas
Atendendo a inúmeros pedidos, implementamos o perfil ‘agendador de workflows’ – na prática as ações do agendador ficam dentro do perfil de ‘Servidores’.
A ideia aqui é criar um perfil no qual o usuário possa utilizar o agendador e realizar tarefas do tipo ligar / desligar / backup / upgrade / downgrade / etc em servidores à escolha ou contas AWS.
Alguns cenários de uso – fique à vontade para implementar o seu próprio caso de uso!
- delegar a gestão dos agendamentos de economia, backups, etc para uma pessoa da equipe;
- se possuir diversas contas AWS, abrir os agendamentos de uma ou mais para outros usuários;
- se utilizar o Cloud8 na forma WhiteLabel (https://painel.cloud ou URL própria), produtizar o agendador e oferecer mais funcionalidades para o seu cliente final;
- é possível combinar este perfil com outros como gerenciar DNS, Banco de dados, métricas, etc – customize um painel de controle por usuário / cliente!
Veja as ações implementadas até o momento. Tendo alguma necessidade de outro agendamento, avise-nos!
Custos: rateio e tags de Backups / Snapshots, Lambda, +melhorias
Um dos maiores pedidos pendentes com AWS, em termos de custos, era o rateio de backup. Até então, o AWS publicava uma única linha de custos de backup / snapshot por região:
$0.05 per GB-Month of snapshot data stored – US East (Northern Virginia) US$24.49 Uso: 489.87 GB
Ou seja, não era possível saber o quanto cada servidor gastou de backup e ratear o custo por tag.
Finalmente, este cenário foi resolvido e o Cloud8 já o suporta. Para consultar os dados detalhados dos backups, pode fazer de 2 formas:
- análise de custos individual de cada servidor – clique no link de custos na lista de servidores e em seguida na aba ‘Tabelas’. Verá o custo de snapshot de cada disco e o espaço ocupado;
- análise geral – clicando no relatório de Tags e expandindo até o produto “EC2 / Backups”. Lembre-se ainda que pode criar alertas de custo e uso, relatórios e estimativas em quaisquer combinações de dados;
Lambda: o Cloud8 mostra as funções Lambda que foram invocadas – nome, número de vezes, segundos utilizados, por tags, etc – de forma que possa fazer rateio e analisar os custos. No relatório de Produtos, expanda o produto “AWS Lambda” e logo após “Regiões” já verá o ID das funções invocadas e os seus detalhes de uso e custo.
Sobre as tags – importante: Para que acompanhe a alocação de custos pelas tags dos snapshots, é necessário, logicamente, que crie as tags nos snapshots. Tendo em vista que o AWS não faz isto automaticamente, o Cloud8 assume a responsabilidade de propagar as tags marcadas para a gestão dos custos até os seus respectivos backups e snapshots quando o agendamento de backup é feito dentro do agendador de workflows.
Além de tudo isto, ainda criamos um botão de download em CSV dos dados detalhados que se encontra na visão “Tabelas”. Com este CSV baixado, pode manipular os dados da forma com que precisar.
Métricas: Queue Length
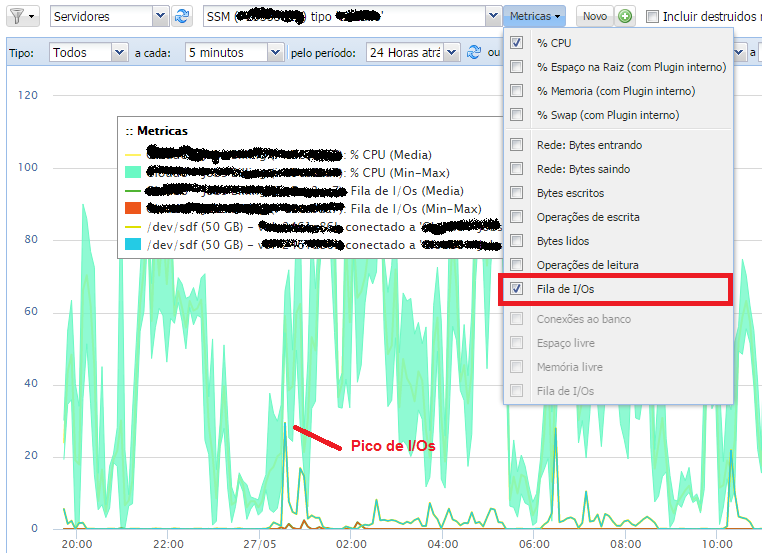
Incluímos uma métrica muito importante para a análise de desempenho dos seus servidores EC2 e RDS: tamanho da fila de I/O nos discos.
Geralmente, para fins de dimensionamento de um servidor, foca-se em demasiado na análise do consumo de CPU – caso o uso de CPU chegue perto de 100%, a conclusão pode ser a necessidade de um upgrade e vice-versa. Isto nem sempre pode ser verdade.
A fila de I/O de disco indica se a escrita e leitura de dados estão sendo executadas de forma performática. Se houver fila, há um gargalo no disco. Este gargalo, por sua vez, pode contingenciar processos no sistema operacional que aumentam o uso de CPU. Desta forma, juntamente com a CPU, vale analisar o Queue Length. A conclusão pode ser que é necessário uma mudança do disco: trocar a família de instâncias para uma com mais performance de I/O, de magnético para SSD, aumentar o tamanho do SSD (+ IOPS) ou até mesmo usar IOPS provisionado (veja esta apresentação – a partir do slide 41 – Queue Length até 8 estaria OK)
No Cloud8, você pode plotar as métricas de CPU e Queue Length de uma única vez. Selecione o(s) servidor/disco/banco de dados e escolha CPU + Queue Length. É possível ainda adicionar o Queue Length de cada disco que o servidor possuir e depois gravar um relatório (ícone do ‘Filtro’) para acesso mais tarde.
Outros
Seguem outras melhorias e correções que merecem destaque:
- FinOps: suporte a custos de Chime, Connect e Lex;
- FinOps: atualização dos preços das instâncias M4;
- RDS: alerta de promoção de Aurora read-only para master, alerta de erro de conversão de InnoDB na migração para Aurora, alerta para Performance Insights desabilitado, patch aplicado que não precisou de reboot;
- Perfis: ação de ver ‘Backup status’ e ‘Acessar servidor’ no perfil tipo ‘servidores customizados’;
- Segurança: alerta se CloudTrail parar de logar eventos;
- Automação: quebra das notificações em 2 emails – sucesso e erro e não mais um único email para os dois cenários;
- Relatórios agendados: novo relatório de servidores há muito tempo desligados – útil para entender se pode transformar este servidor em AMI e portanto, economizar;
- Catálogo de componentes: possibilidade de fazer o download em CSV de todos os Load Balancers e IP Elásticos;
- Sincronização: opção de não receber avisos de servidores criados por Auto Scaling, Beanstalk – eles continuam aparecendo na lista de servidores e todas as análises de custos e métricas ainda são válidas;
- Sincronização: o email de aviso de criação de novos servidores marca quando o servidor é do tipo Auto Scaling;
Dúvidas, críticas, sugestões? Entre em contato!